How do I get the latest Azure DP-200 exam practice question tips? Brain2dumps shares the latest DP-200 exam dump, DP-200 pdf,
And online hands-on testing free to improve skills and experience, 98.5% of the test pass rate selected Lead4 through DP-200 dump: https://www.leads4pass.com/dp-200.html (latest update)
Microsoft Azure DP-200 exam pdf free download
[PDF Q1-Q13] Free Microsoft dp-200 pdf dumps download from Google Drive: https://drive.google.com/open?id=1nuqnlf7cWW0XCqnomHVX0_o72O6U7z40
Exam DP-200: Implementing an Azure Data Solution: https://docs.microsoft.com/en-us/learn/certifications/exams/dp-200
Skills measured
- The content of this exam will be updated on March 31, 2020. Please download the skills measured document below to see what will be changing.
- NOTE: The bullets that appear below each of the skills measured in the document below are intended to illustrate how we are assessing that skill. This list is not definitive or exhaustive.
- Implement data storage solutions (40-45%)
- Manage and develop data processing (25-30%)
- Monitor and optimize data solutions (30-35%)
Real and effective Microsoft Azure DP-200 Exam Practice Questions
QUESTION 1
You plan to perform batch processing in Azure Databricks once daily. Which type of Databricks cluster should you use?
A. job
B. interactive
C. High Concurrency
Correct Answer: A
Example: Scheduled batch workloads (data engineers running ETL jobs)
This scenario involves running batch job JARs and notebooks on a regular cadence through the Databricks platform.
The suggested best practice is to launch a new cluster for each run of critical jobs. This helps avoid any issues (failures,
missing SLA, and so on) due to an existing workload (noisy neighbor) on a shared cluster.
Note: Azure Databricks has two types of clusters: interactive and automated. You use interactive clusters to analyze
data collaboratively with interactive notebooks. You use automated clusters to run fast and robust automated jobs.
References:
https://docs.databricks.com/administration-guide/cloud-configurations/aws/cmbp.html#scenario-3-scheduled-batchworkloads-data-engineers-running-etl-jobs
QUESTION 2
You manage security for a database that supports a line of business application.
Private and personal data stored in the database must be protected and encrypted.
You need to configure the database to use Transparent Data Encryption (TDE).
Which five actions should you perform in sequence? To answer, select the appropriate actions from the list of actions to
the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:

Step 1: Create a master key
Step 2: Create or obtain a certificate protected by the master key
Step 3: Set the context to the company database
Step 4: Create a database encryption key and protect it by the certificate
Step 5: Set the database to use encryption
Example code: USE master; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = \\’\\’; go CREATE
CERTIFICATE MyServerCert WITH SUBJECT = \\’My DEK Certificate\\’; go USE AdventureWorks2012; GO CREATE
DATABASE ENCRYPTION KEY WITH ALGORITHM = AES_128 ENCRYPTION BY SERVER CERTIFICATE
MyServerCert; GO ALTER DATABASE AdventureWorks2012 SET ENCRYPTION ON; GO
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/transparent-data-encryption
QUESTION 3
You implement an Azure SQL Data Warehouse instance.
You plan to migrate the largest fact table to Azure SQL Data Warehouse. The table resides on Microsoft SQL Server on-premises and is 10 terabytes (TB) in size. Incoming queries use the primary key Sale Key column to retrieve data as displayed in the following table: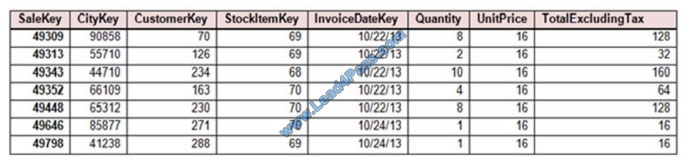
You need to distribute the large fact table across multiple nodes to optimize the performance of the table. Which technology
should you use?
A. hash distributed table with clustered ColumnStore index
B. hash distributed table with a clustered index
C. heap table with distribution replicate
D. round-robin distributed a table with a clustered index
E. round-robin distributed table with clustered ColumnStore index
Correct Answer: A
Hash-distributed tables improve query performance on large fact tables.
Columnstore indexes can achieve up to 100x better performance on analytics and data warehousing workloads and up
to 10x better data compression than traditional rowstore indexes.
Incorrect Answers:
D, E: Round-robin tables are useful for improving loading speed.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-query-performance
QUESTION 4
You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following
three workloads:
A workload for data engineers who will use Python and SQL A workload for jobs that will run notebooks that use Python,
Spark, Scala, and SQL A workload that data scientists will use to perform ad hoc analysis in Scala and R
The enterprise architecture team at your company identifies the following standards for Databricks environments:
The data engineers must share a cluster.
The job cluster will be managed by using a request process whereby data scientists and data engineers provide
packaged notebooks for deployment to the cluster.
All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity.
Currently, there are three data scientists.
You need to create the Databrick clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a
Standard cluster for the jobs.
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
We would need a High Concurrency cluster for the jobs.
Note:
Standard clusters are recommended for a single user. Standard can run workloads developed in any language: Python,
R, Scala, and SQL.
A high concurrency cluster is a managed cloud resource. The key benefits of high concurrency clusters are that they
provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies.
References:
https://docs.azuredatabricks.net/clusters/configure.html
QUESTION 5
You are creating a managed data warehouse solution on Microsoft Azure.
You must use PolyBase to retrieve data from Azure Blob storage that resides in parquet format and toad the data into a
large table called FactSalesOrderDetails.
You need to configure Azure SQL Data Warehouse to receive the data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to
the answer area and arrange them in the correct order.
Select and Place: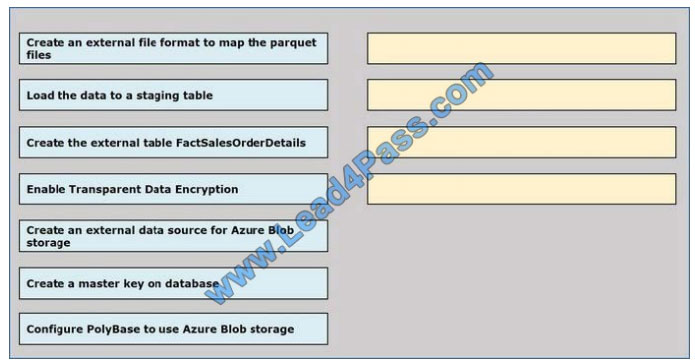
Correct Answer:
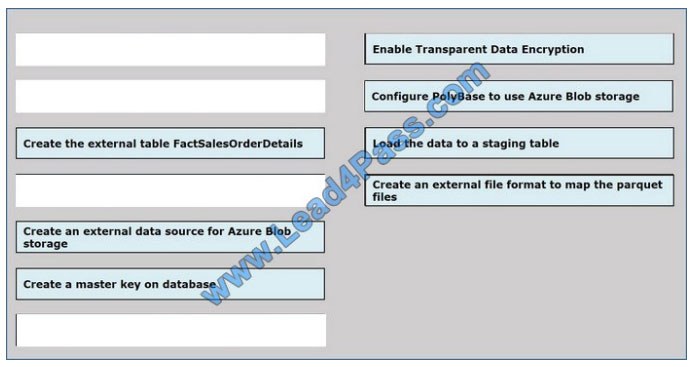
QUESTION 6
You need to mask tier 1 data. Which functions should you use? To answer, select the appropriate option in the answer
area. NOTE: Each correct selection is worth one point.
Hot Area: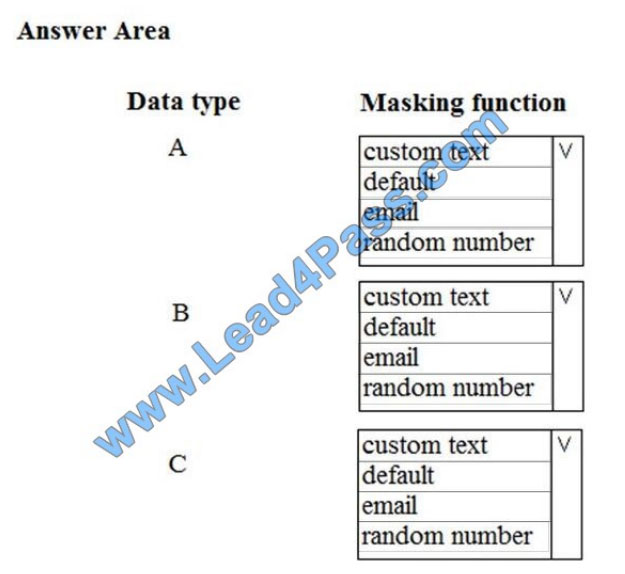
Correct Answer:
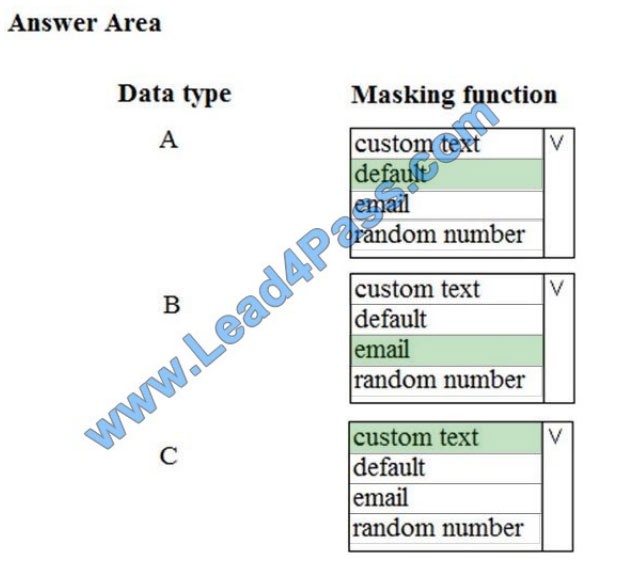
A: Default
Full masking according to the data types of the designated fields.
For string data types, use XXXX or fewer Xs if the size of the field is less than 4 characters (char, nchar, varchar,
varchar, text, next).
B: email
C: Custom text
Custom StringMasking method which exposes the first and last letters and adds a custom padding string in the middle.
prefix,[padding],suffix
Tier 1 Database must implement data masking using the following masking logic:

References: https://docs.microsoft.com/en-us/sql/relational-databases/security/dynamic-data-masking
QUESTION 7
You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and
authorization for deployments? To answer, select the appropriate options in the answer choices. NOTE: Each correct
selection is worth one point.
Hot Area: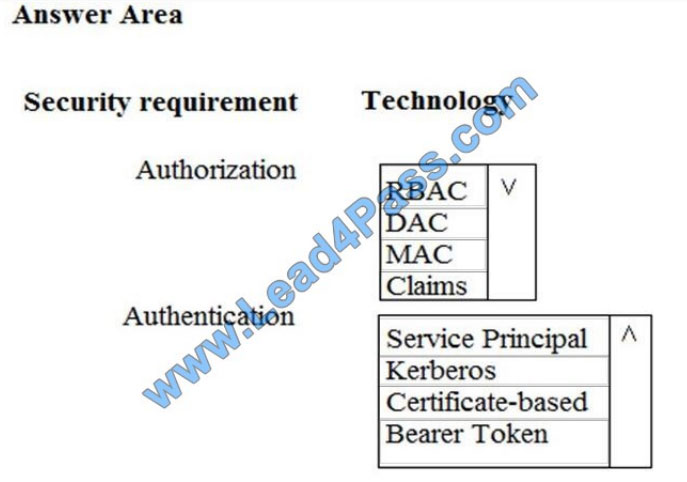
Correct Answer:

Explanation/Reference:
The way you control access to resources using RBAC is to create role assignments. This is a key concept to understand
QUESTION 8
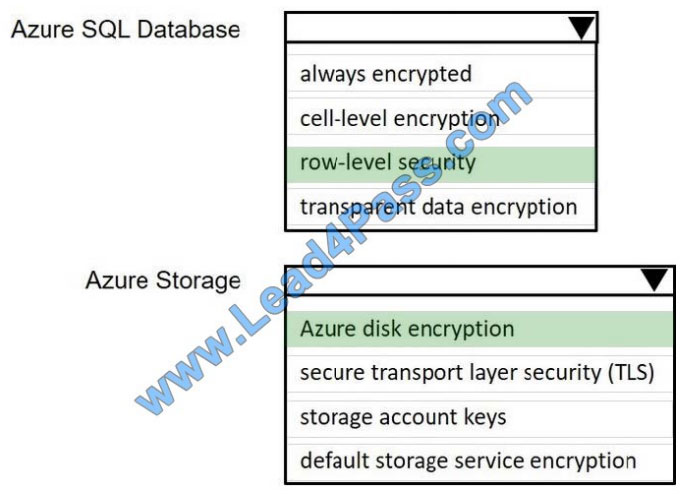
Your company uses Azure SQL Database and Azure Blob storage.
All data at rest must be encrypted by using the company\\’s own key. The solution must minimize administrative effort
and the impact on applications that use the database.
You need to configure security.
What should you implement? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: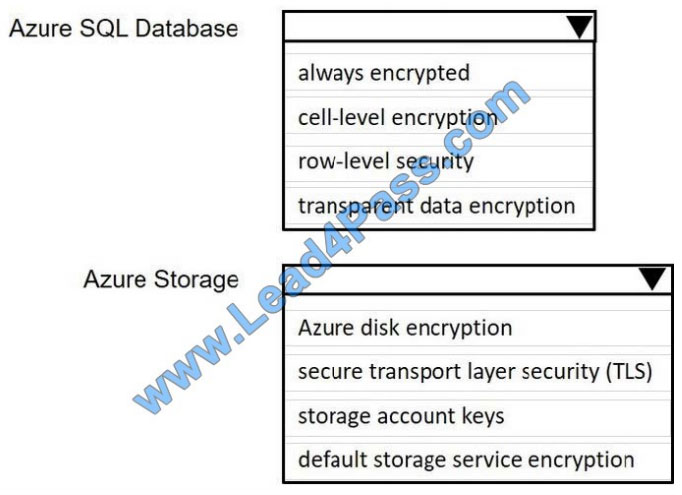
Correct Answer:
QUESTION 9
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be
ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1.
Create a remote service binding pointing to the Azure Data Lake Gen 2 storage account
2.
Create an external file format and external table using the external data source
3.
Load the data using the CREATE TABLE AS SELECT statement
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
You need to create an external file format and external table from an external data source, instead of from a remote
service binding pointing.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lakestore
QUESTION 10
You have an Azure Storage account that contains 100 GB of files. The files contain text and numerical values. 75% of
the rows contain description data that has an average length of 1.1 MB.
You plan to copy the data from the storage account to an Azure SQL data warehouse.
You need to prepare the files to ensure that the data copies quickly.
Solution: You modify the files to ensure that each row is more than 1 MB.
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
Instead, modify the files to ensure that each row is less than 1 MB.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
QUESTION 11
You develop data engineering solutions for a company.
A project requires the deployment of resources to Microsoft Azure for batch data processing on Azure HDInsight. Batch
processing will run daily and must:
Scale to minimize costs
Be monitored for cluster performance
You need to recommend a tool that will monitor clusters and provide information to suggest how to scale.
Solution: Monitor clusters by using Azure Log Analytics and HDInsight cluster management solutions.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
HDInsight provides cluster-specific management solutions that you can add for Azure Monitor logs. Management
solutions add functionality to Azure Monitor logs, providing additional data and analysis tools. These solutions collect
important performance metrics from your HDInsight clusters and provide the tools to search the metrics. These solutions
also provide visualizations and dashboards for most cluster types supported in HDInsight. By using the metrics that you
collect with the solution, you can create custom monitoring rules and alerts.
References: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-oms-log-analytics-tutorial
QUESTION 12
A company is designing a hybrid solution to synchronize data and on-premises Microsoft SQL Server database to Azure
SQL Database.
You must perform an assessment of databases to determine whether data will move without compatibility issues. You
need to perform the assessment.
Which tool should you use?
A. SQL Server Migration Assistant (SSMA)
B. Microsoft Assessment and Planning Toolkit
C. SQL Vulnerability Assessment (VA)
D. Azure SQL Data Sync
E. Data Migration Assistant (DMA)
Correct Answer: E
The Data Migration Assistant (DMA) helps you upgrade to a modern data platform by detecting compatibility issues that
can impact database functionality in your new version of SQL Server or Azure SQL Database. DMA recommends
performance and reliability improvements for your target environment and allows you to move your schema, data, and
uncontained objects from your source server to your target server.
References: https://docs.microsoft.com/en-us/sql/dma/dma-overview
QUESTION 13
You are developing a data engineering solution for a company. The solution will store a large set of key-value pair data
by using Microsoft Azure Cosmos DB.
The solution has the following requirements:
Data must be partitioned into multiple containers.
Data containers must be configured separately.
Data must be accessible from applications hosted around the world.
The solution must minimize latency.
You need to provision Azure Cosmos DB.
A. Cosmos account-level throughput.
B. Provision an Azure Cosmos DB account with the Azure Table API. Enable geo-redundancy.
C. Configure table-level throughput.
D. Replicate the data globally by manually adding regions to the Azure Cosmos DB account.
E. Provision an Azure Cosmos DB account with the Azure Table API. Enable multi-region writes.
Correct Answer: E
The scale read and write throughput globally. You can enable every region to be writable and elastically scale reads and
writes all around the world. The throughput that your application configures on an Azure Cosmos database or a
container is guaranteed to be delivered across all regions associated with your Azure Cosmos account. The provisioned
throughput is guaranteed up by financially-backed SLAs.
References: https://docs.microsoft.com/en-us/azure/cosmos-db/distribute-data-globally
Share leads4pass discount codes for free 2020

leads4pass Reviews
leads4pass offers the latest exam exercise questions for free! Microsoft exam questions are updated throughout the year.
leads4pass has many professional exam experts! Guaranteed valid passing of the exam! The highest pass rate, the highest cost-effective!
Help you pass the exam easily on your first attempt.
What you need to know:
Brain2dumps shares the latest Microsoft DP-200 exam dumps, DP-200 pdf, DP-200 exam exercise questions for free.
You can improve your skills and exam experience online to get complete exam questions and answers guaranteed to pass the
exam we recommend leads4pass DP-200 exam dumps
Latest update leads4pass DP-200 exam dumps: https://www.leads4pass.com/dp-200.html (184 Q&As)
[Q1-Q13 PDF] Free Microsoft DP-200 pdf dumps download from Google Drive: https://drive.google.com/open?id=1nuqnlf7cWW0XCqnomHVX0_o72O6U7z40

Comments are closed.