How do I get the latest Azure DP-201 exam practice question tips? Brain2dumps shares the latest DP-201 exam dump, DP-201 pdf,
And online hands-on testing free to improve skills and experience, 98.5% of the test pass rate selected Lead4 through DP-201 dump: https://www.leads4pass.com/dp-201.html (latest update)
Microsoft Azure DP-201 exam pdf free download
[PDF Q1-Q13] Free Microsoft DP-201 pdf dumps download from Google Drive: https://drive.google.com/open?id=1FBB57K45lNPc0xvTkMqwGiykdhBr4ebr
Exam DP-201: Designing an Azure Data Solution: https://docs.microsoft.com/en-us/learn/certifications/exams/dp-201
Skills measured
- The content of this exam will be updated on March 26, 2020. Please download the skills measured document below to see what will be changing.
- NOTE: The bullets that appear below each of the skills measured in the document below are intended to illustrate how we are assessing that skill. This list is not definitive or exhaustive.
- Design Azure data storage solutions (40-45%)
- Design data processing solutions (25-30%)
- Design for data security and compliance (25-30%)
Real and effective Microsoft Azure DP-201 Exam Practice Questions
QUESTION 1
You are planning a design pattern based on the Lambda architecture as shown in the exhibit.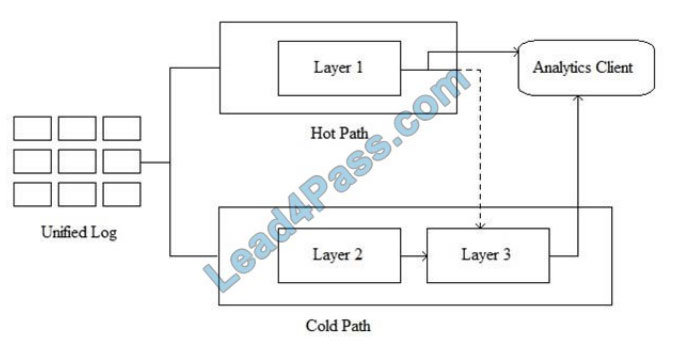
Which Azure service should you use for the hot path?
A. Azure Databricks
B. Azure SQL Database
C. Azure Data Factory
D. Azure Database for PostgreSQL
Correct Answer: A
In Azure, all of the following data stores will meet the core requirements supporting real-time processing:
1.
Apache Spark in Azure Databricks
2.
Azure Stream Analytics
3.
HDInsight with Spark Streaming
4.
HDInsight with Storm
5.
Azure Functions
6.
Azure App Service WebJobs
Note: Lambda architectures use batch-processing, stream-processing, and a serving layer to minimize the latency
involved in querying big data.
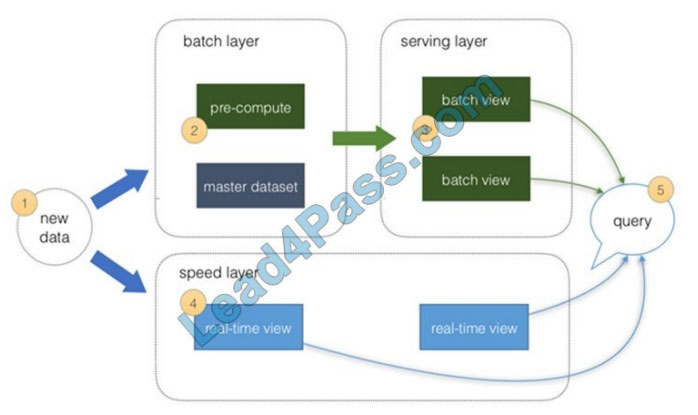
References: https://azure.microsoft.com/en-us/blog/lambda-architecture-using-azure-cosmosdb-faster-performance-lowtco-low-devops/
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/stream-processing
QUESTION 2
You need to design the data loading pipeline for Planning Assistance.
What should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology
may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view
content.
NOTE: Each correct selection is worth one point.
Hot Area: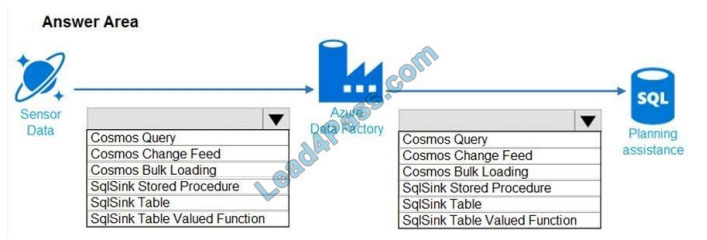
Correct Answer:
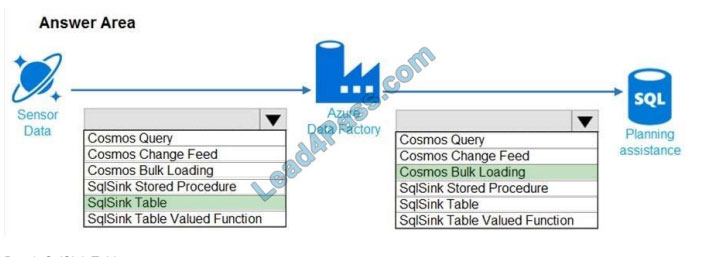
Box 1: SqlSink Table
Sensor data must be stored in a Cosmos DB named try data in a collection named SensorData
Box 2: Cosmos Bulk Loading
Use Copy Activity in Azure Data Factory to copy data from and to Azure Cosmos DB (SQL API).
Scenario: Data from the Sensor Data collection will automatically be loaded into the Planning Assistance database once
a week by using the Azure Data Factory. You must be able to manually trigger the data load process.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
References:
https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-cosmos-db
QUESTION 3
A company is evaluating data storage solutions.
You need to recommend a data storage solution that meets the following requirements:
1.
Minimize costs for storing blob objects.
2.
Optimize access for data that is infrequently accessed.
3.
Data must be stored for at least 30 days.
4.
Data availability must be at least 99 percent. What should you recommend?
A. Premium
B. Cold
C. Hot
D. Archive
Correct Answer: B
Azure\\’s cool storage tier, also known as Azure cool Blob storage, is for infrequently-accessed data that needs to be
stored for a minimum of 30 days. Typical use cases include backing up data before tiering to archival systems, legal
data, media files, system audit information, datasets used for big data analysis and more.
The storage cost for this Azure cold storage tier is lower than that of the hot storage tier. Since it is expected that the data
stored in this tier will be accessed less frequently, the data access charges are high when compared to the hot tier. There
are no additional changes required in your applications as these tiers can be accessed using APIs in the same manner
that you access Azure storage.
References: https://cloud.netapp.com/blog/low-cost-storage-options-on-azure
QUESTION 4
HOTSPOT
You are designing a data processing solution that will run as a Spark job on an HDInsight cluster. The solution will be
used to provide near real-time information about online ordering for a retailer.
The solution must include a page on the company intranet that displays summary information.
The summary information page must meet the following requirements:
1.
Display a summary of sales to date grouped by product categories, price range, and review scope.
2.
Display sales summary information including total sales, sales as compared to one day ago and sales as compared to
one year ago.
3.
Reflect information for new orders as quickly as possible.
You need to recommend a design for the solution.
What should you recommend? To answer, select the appropriate configuration in the answer area.
Hot Area:
Correct Answer:
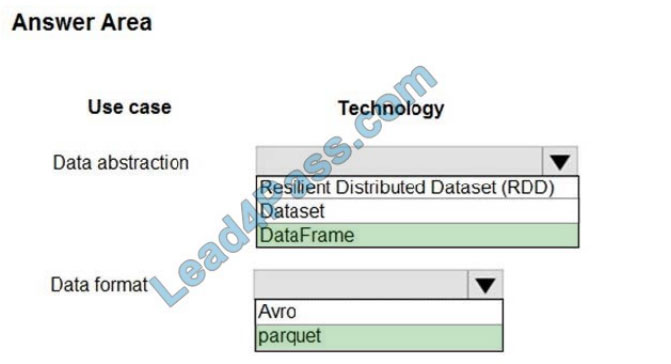
Explanation:
Box 1: DataFrame
DataFrames
Best choice in most situations.
It provides query optimization through Catalyst.
Whole-stage code generation.
Direct memory access.
Low garbage collection (GC) overhead.
Not as developer-friendly as DataSets, as there are no compile-time checks or domain object programming.
Box 2: parquet
The best format for performance is parquet with snappy compression, which is the default in Spark 2.x. Parquet stores
data in columnar format, and is highly optimized in Spark.
Incorrect Answers:
DataSets
Good in complex ETL pipelines where the performance impact is acceptable.
Not good in aggregations where the performance impact can be considerable.
RDDs
You do not need to use RDDs unless you need to build a new custom RDD.
No query optimization through Catalyst.
No whole-stage code generation.
High GC overhead.
References: https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-perf
QUESTION 5
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen.
You have an Azure SQL database that has columns. The columns contain sensitive Personally Identifiable Information
(PII) data.
You need to design a solution that tracks and stores all the queries executed against the PII data. You must be able to
review the data in Azure Monitor, and the data must be available for at least 45 days.
Solution: You add classifications to the columns that contain sensitive data. You turn on Auditing and set the audit log
destination to use Azure Blob storage.
Does this meet the goal?
A. Yes
B. No
Correct Answer: A
Auditing has been enhanced to log sensitivity classifications or labels of the actual data that were returned by the query.
This would enable you to gain insights on who is accessing sensitive data.
References: https://azure.microsoft.com/en-us/blog/announcing-public-preview-of-data-discovery-classification-formicrosoft-azure-sql-data-warehouse/
QUESTION 6
You need to design the Planning Assistance database.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area: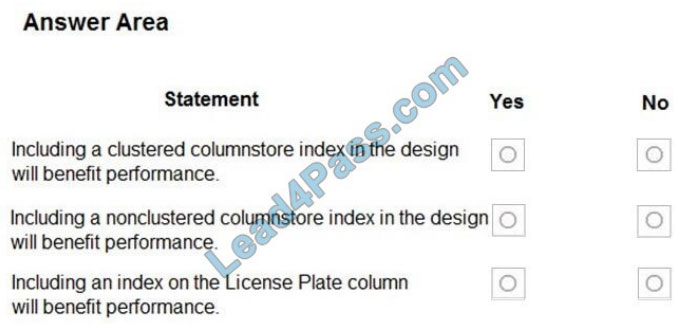
Correct Answer:
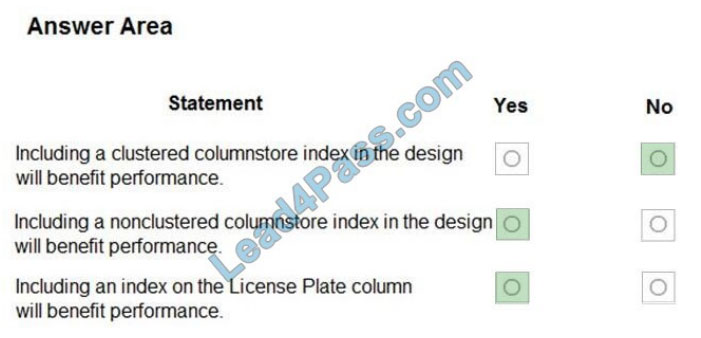
Box 1: No
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
Box 2: Yes
Box 3: Yes
Planning Assistance database will include reports tracking the travel of a single-vehicle
QUESTION 7
You plan to migrate data to Azure SQL Database.
The database must remain synchronized with updates to Microsoft Azure and SQL Server.
You need to set up the database as a subscriber.
What should you recommend?
A. Azure Data Factory
B. SQL Server Data Tools
C. Data Migration Assistant
D. SQL Server Agent for SQL Server 2017 or later
E. SQL Server Management Studio 17.9.1 or later
Correct Answer: E
To set up the database as a subscriber we need to configure database replication. You can use SQL Server
Management Studio to configure replication. Use the latest versions of SQL Server Management Studio in order to be
able to use all the features of the Azure SQL Database.
References: https://www.sqlshack.com/sql-server-database-migration-to-azure-sql-database-using-sql-servertransactional-replication/
QUESTION 8
HOTSPOT
A company has locations in North America and Europe. The company uses the Azure SQL Database to support business
apps.
Employees must be able to access the app data in case of a region-wide outage. A multi-region availability solution is
needed with the following requirements:
1.
Read-access to data in a secondary region must be available only in case of an outage of the primary region.
2.
The Azure SQL Database compute and storage layers must be integrated and replicated together.
You need to design the multi-region high availability solution.
What should you recommend? To answer, select the appropriate values in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

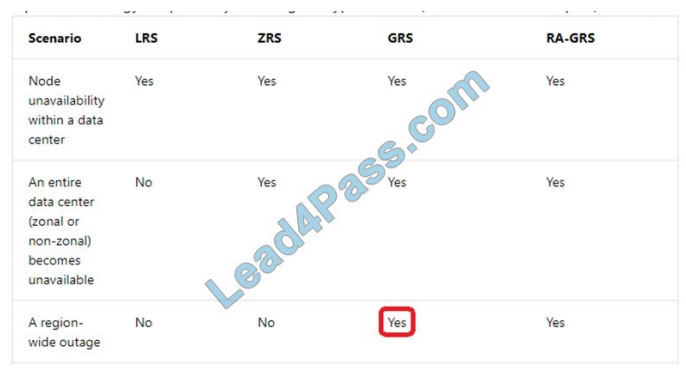
Box 1: Standard
The following table describes the types of storage accounts and their capabilities:
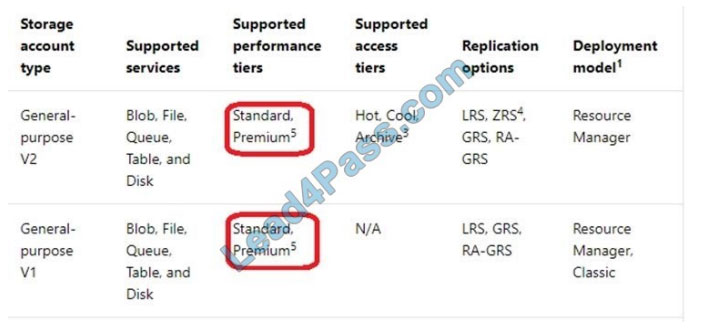
Box 2: Geo-redundant storage
If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a
disaster in which the primary region isn\\’t recoverable.
Note: If you opt for GRS, you have two related options to choose from:
GRS replicates your data to another data center in a secondary region, but that data is available to be read-only if
Microsoft initiates a failover from the primary to the secondary region. Read-access geo-redundant storage (RA-GRS) is
based on
GRS. RA-GRS replicates your data to another data center in a secondary region and also provides you with the option
to read from the secondary region. With RA-GRS, you can read from the secondary region regardless of whether
Microsoft initiates a failover from the primary to the secondary region.
References: https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction
https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
QUESTION 9
What should you recommend to prevent users outside the Litware on-premises network from accessing the analytical
datastore?
A. a server-level virtual network rule
B. a database-level virtual network rule
C. a database-level firewall IP rule
D. a server-level firewall IP rule
Correct Answer: A
Virtual network rules are one firewall security feature that controls whether the database server for your single
databases and elastic pool in Azure SQL Database or for your databases in SQL Data Warehouse accepts
communications that are sent from particular subnets in virtual networks.
Server-level, not database-level: Each virtual network rule applies to your whole Azure SQL Database server, not just to
one particular database on the server. In other words, virtual network rule applies at the server-level, not at the
database-level.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-vnet-service-endpoint-rule-overview
QUESTION 10
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen.
You plan to store delimited text files in an Azure Data Lake Storage account that will be organized into the department
folders.
You need to configure data access so that users see only the files in their respective department folder.
Solution: From the storage account, you enable a hierarchical namespace, and you use RBAC.
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
Disable the hierarchical namespace. And instead of RBAC use access control lists (ACLs).
Note: Azure Data Lake Storage implements an access control model that derives from HDFS, which in turn derives from
the POSIX access control model.
Blob container ACLs does not support the hierarchical namespace, so it must be disabled.
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-known-issues
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-access-control
QUESTION 11
DRAG DROP
You discover that the highest chance of corruption or bad data occurs during nightly inventory loads.
You need to ensure that you can quickly restore the data to its state before the nightly load and avoid missing any
streaming data.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions
to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
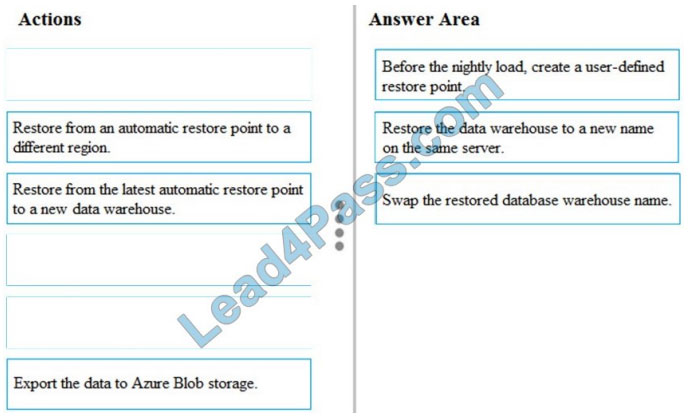
Step 1: Before the nightly load, create a user-defined restore point SQL Data Warehouse performs a geo-backup once
per day to a paired data center. The RPO for a geo-restore is 24 hours. If you require a shorter RPO for geo-backups,
you can create a user-defined restore point and restore from the newly created restore point to a new data warehouse in
a different region.
Step 2: Restore the data warehouse to a new name on the same server.
Step 3: Swap the restored database warehouse name.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
QUESTION 12
You have a MongoDB database that you plan to migrate to an Azure Cosmos DB account that uses the MongoDB API.
During testing, you discover that the migration takes longer than expected.
You need to recommend a solution that will reduce the amount of time it takes to migrate the data.
What are the two possible recommendations to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Increase the Request Units (RUs).
B. Turn off indexing.
C. Add a write region.
D. Create unique indexes.
E. Create compound indexes.
Correct Answer: AB
A: Increase the throughput during the migration by increasing the Request Units (RUs).
For customers that are migrating many collections within a database, it is strongly recommended to configure database-level throughput. You must make this choice when you create the database. The minimum database-level throughput
capacity is 400 RU/sec. Each collection-sharing database-level throughput requires at least 100 RU/sec.
B: By default, Azure Cosmos DB indexes all your data fields upon ingestion. You can modify the indexing policy in
Azure Cosmos DB at any time. In fact, it is often recommended to turn off indexing when migrating data, and then turn it
back on when the data is already in Cosmos DB.
References: https://docs.microsoft.com/bs-latn-ba/Azure/cosmos-db/mongodb-pre-migration
QUESTION 13
DRAG DROP
Which three actions should you perform in sequence to allow FoodPrep access to the analytical data store? To answer,
move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place: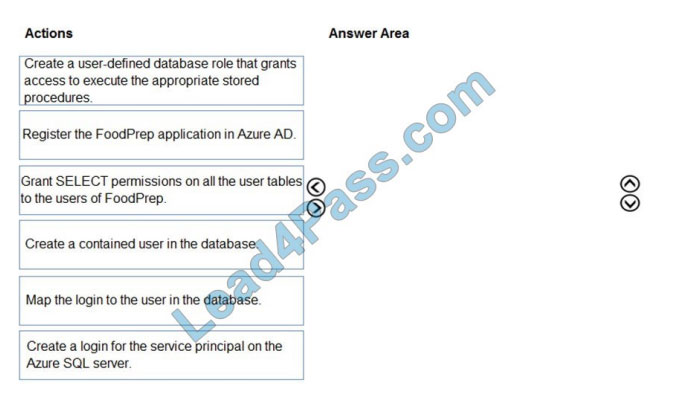
Correct Answer:
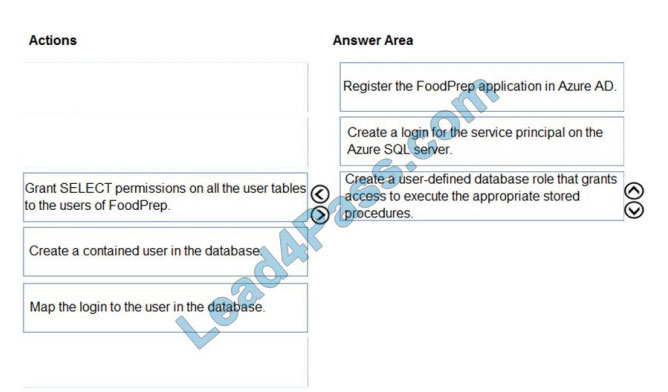
Scenario: Litware will build a custom application named FoodPrep to provide store employees with the calculation
results of how many prepared food items to produce every four hours.
Step 1: Register the FoodPrep application in Azure AD
You create your Azure AD application and service principal.
Step 2: Create a login for the service principal on the Azure SQL Server
Step 3: Create a user-defined database role that grants access.
To access resources in your subscription, you must assign the application to a role.
You can then assign the required permissions to the service principal.
Reference:
https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal
Share leads4pass discount codes for free 2020

leads4pass Reviews
leads4pass offers the latest exam exercise questions for free! Microsoft exam questions are updated throughout the year.
leads4pass has many professional exam experts! Guaranteed valid passing of the exam! The highest pass rate, the highest cost-effective!
Help you pass the exam easily on your first attempt.
What you need to know:
Brain2dumps shares the latest Microsoft DP-201 exam dumps, DP-201 pdf, DP-201 exam exercise questions for free.
You can improve your skills and exam experience online to get complete exam questions and answers guaranteed to pass the exam we recommend leads4pass DP-201 exam dumps
Latest update leads4pass DP-201 exam dumps: https://www.leads4pass.com/dp-201.html (145 Q&As)
[Q1-Q13 PDF] Free Microsoft DP-201 pdf dumps download from Google Drive: https://docs.microsoft.com/en-us/learn/certifications/exams/dp-201

Comments are closed.